F_m(x) = F_(m-1)(x) + γ * h_m(x)
這裡,是實際觀測值,
是前一個模型的預測。
更新模型 。
重複上述過程,直到達到停止條件。
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest, f_classif
# 載入數據
data = load_iris()
X = data.data
y = data.target
# 特徵工程
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 特徵選擇
k_best = SelectKBest(f_classif, k=2)
X = k_best.fit_transform(X, y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 創建LightGBM分類器並配置超參數
params = {
'objective': 'multiclass',
'num_class': 3, # 三個類別
'boosting_type': 'gbdt',
'metric': 'multi_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
}
model = lgb.LGBMClassifier(**params)
# 訓練模型
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 計算準確度
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 混淆矩陣
confusion = confusion_matrix(y_test, y_pred)
# 分類報告
class_report = classification_report(y_test, y_pred)
lgb.plot_importance(model, max_num_features=2)
plt.show()
plt.imshow(confusion, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = [0, 1, 2]
plt.xticks(tick_marks, [str(i) for i in range(3)])
plt.yticks(tick_marks, [str(i) for i in range(3)])
plt.xlabel("Predicted")
plt.ylabel("True")
for i in range(3):
for j in range(3):
plt.text(j, i, confusion[i, j], horizontalalignment="center", color="white" if confusion[i, j] > confusion.max() / 2 else "black")
plt.show()
print("Classification Report:\n", class_report)
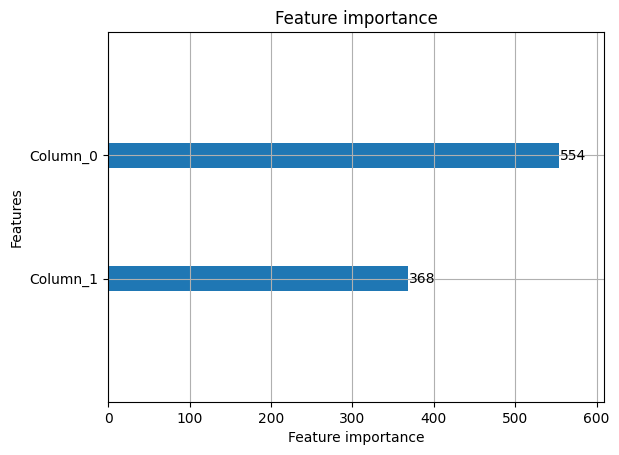
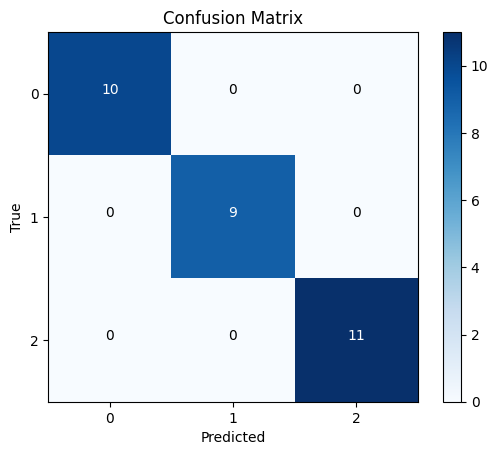
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30

